Commercial
Some software projects I have delivered in the last few years through my company Isogonal.
I'm interested in systems that take actions autonomously, as opposed to delivering 'insights'. I'm really excited about the challenges in integrating LLMs into automated systems over the next several years.
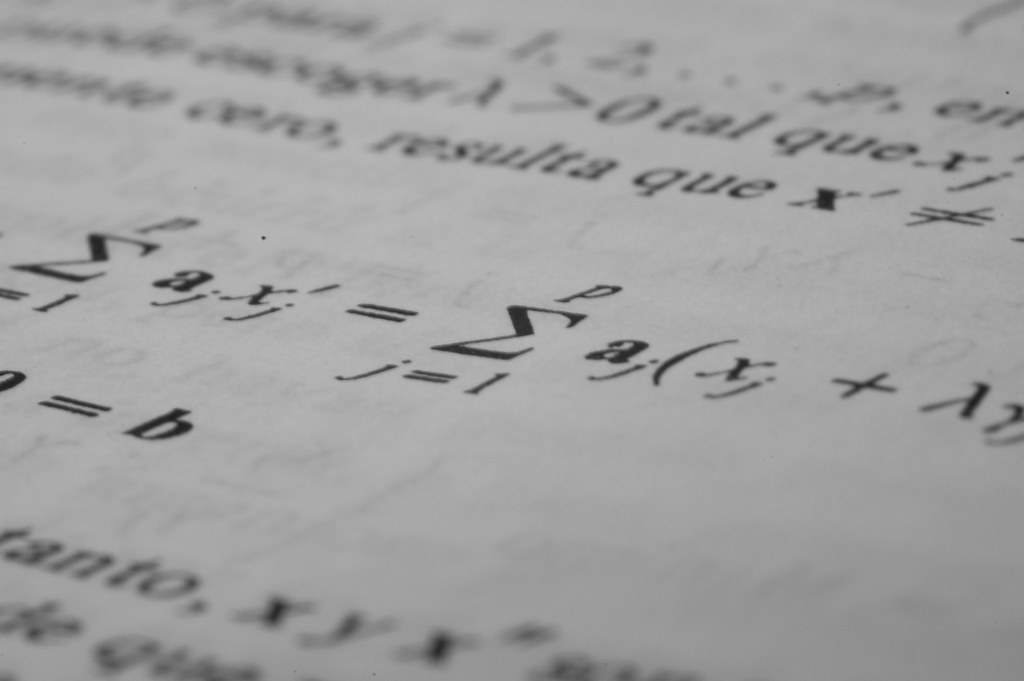
Automated logistics cost optimization
Linear programming
Combinatorial optimization
Reinforcement learning
SAP and Kinaxis integration
Multi-tenant enterprise SaaS
I built a multi-tenant enterprise SaaS platform that lowers costs in large transportation networks by smoothing shipping volumes over a month-long horizon. This is in use by multiple Fortune 500 organisations.
The platform integrates with client ERP systems and ingests planned stock transfers across hundreds of locations and thousands of lanes. The optimization engine creates incentives for reducing carrier costs, utilizing capacity effectively, constant daily shipping volumes and delivering on time.
It utilizes constraints for daily location transport capacity, location storage capacity, carrier and mode capacity on each lane, as well as information such as locations being closed on given days. It can accomodate unique penalities for individual STRs and custom penalties and incentives for days early and late.
As well as incentives, the optimization engine manages hundreds of thousands of hard and soft constraints for time-dependent location, carrier, mode, and lane capacities.
At the core of the optimization engine is a linear program. The code also uses custom 3D bin packing heuristics to match pallets to trucks.

Automated industrial work order prioritization
Active learning
Natural language processing
Uncertainty quantification
Hierarchical modeling
The national electrical grid operator in New Zealand approached me to investigate the possibility for automatically prioritising incoming maintenance work orders from external service providers, for equipment across the national grid.
This research project turned into deployed product and a conference paper. The software runs daily, reading information from the Maximo maintenance database, running the calculations, and feeding priorities back into the database.
The web application allows Transpower staff to update training data for new equipment, re-train, and investigate model accuracy without my input. This is crucial for the system to be sustainable - new types of equipment can be introduced into the grid without requiring my ongoing input.
This system was implemented in 2018, is still in use, has prioritized tens of millions of dollars in maintenance expenditure, and annual reviews have demonstrated significantly positive all-up ROI.
For each work order (100,000+) the system runs a processing pipeline estimating probability of loss and loss severity over 5 categories: service performance, financial cost, public safety, worker safety, and environmental impact. The system then estimates cost to remediate. This information is turned into a final priority.
Developing equipment and defect ontologies was key to this project. The existing equipment database was at the wrong granularity - units of equipment that fail often had a one-many relationship with parts in the equipment database. Unsupervised approaches were heavily used to explore the data and iteratively build the ontologies.
Another key piece of the project was capturing organization-wide experiential knowledge. We developed a web app for data entry along with an active learning approach to make the best use of the available input. Among other outputs, this was used to aggregate subjective evaluations of the likelihood of failure for an asset/defect combination into a quantitative estimate.
The processing pipeline involves a hierarchical system of Bayesian generalized linear models, quantifying uncertainty at each step, to generate an equipment and fault ontology node. Subsequent modules then estimate the likelihood and consequence of loss, repair cost, and calculate the final priority score.

Geological data platform
Multi-tenant enterprise web app
Correcting X-Ray fluorescence measurements
This multi-tenant SaaS platform for managing the data produced by minerals exploration companies evolved out of an app I built for my friend. She was spending hours each day maintaining and fixing master spreadsheets for the flood of data produced by staff each day.
This data management platform allows all staff to upload their own spreadsheets with upload-time error checking, applies calculation pipelines automatically, and makes the latest processed data with fine-grained permissions available for download to anyone anywhere.

Lab results delivery portal
PII health information
HL7 and FHIR healthcare data interoperability
White-box penetration testing audit
I developed a results delivery portal for a commercial toxicology lab with thousands of MAU.
This project involved a deep dive into the HL7 and FHIR health data interoperability standards. I had to reverse-engineer 397 tables in the LabEclair LIS system, figure out where the information relating to patient results was stored, and then store these into a downstream database for rendering patient results in PDF form at request time.
It also includes some nice git-like functionality enabling lab users to edit reports downstream of the original source, and then interleaving new data from the source with existing user edits, including the ability to roll back to any previous version while maintaining the edit history.
Due to a desire to keep dependencies to an absolute minmum, I wrote the authentication/ authorization and user management code from scratch, which subsequently passed an externally contracted white-box penetration test. Also, this project is built to be easily maintained for as long as possilble, so the framework stack was kept minimimal - Node.js, Passport, EJS templates, and hand-written CSS.
Open Source
Almost all of the code I've written in the last decade is closed-source. These are a few of the open-source projects
OSISoft PI Historian bulk download tool - 2018
.NET Core
OSISoft PI Historian (now AVEVA Server) is a time-series database used by heavy industry worldwide. Donwloading bulk data (millions of series, terabytes of data) for analytics or ML use is challenging - think Excel integrations with a maximum of 1,000 points per request.
It's now 2023 and this may have changed with an AVEVA cloud solution. However, last I checked, this tool was the only available/open source solution for the bulk download use case. It has been used by engineers at large firms worldwide.
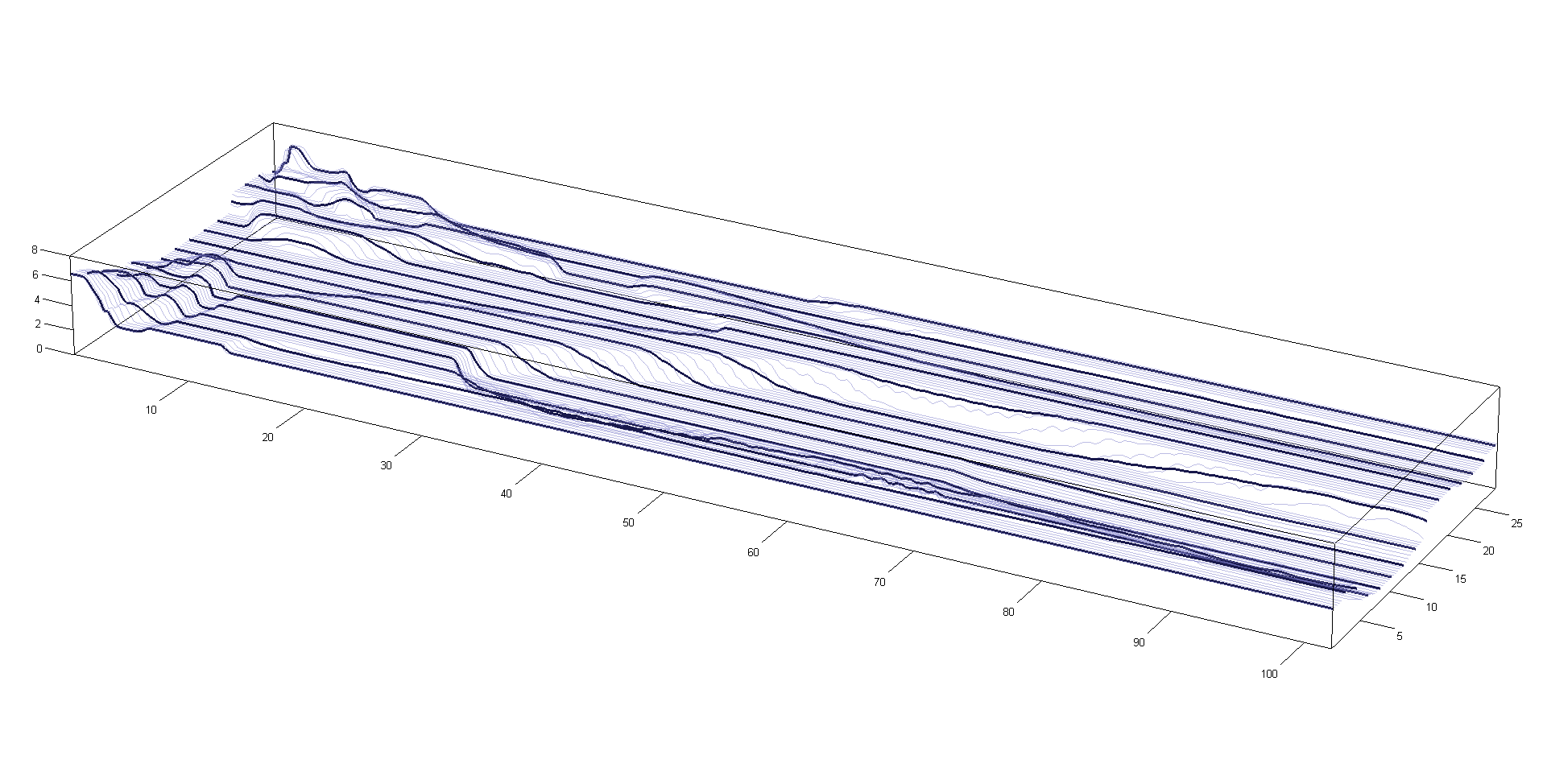
Interpolating a surface point cloud - 2010
Matlab
I wrote this code because I had a raster scan of a very old contour plot - pressure contours from a physical wind tunnel test of a large industrial building. I wanted to turn these pressure contours into distributed loads and finally bending moments along the roof trusses.
First I digitized the contours into a 3D point cloud, with points along the contour lines. Then I made a Delaunay triangulation of the point cloud. Finally I took a set of points along the beam and interpolated the TIN surface at these points. This code (Matlab) conducts the Delaunay triangulation and then efficiently locates the triangle an arbitrary point falls inside and interpolates the point value from the triange surface.